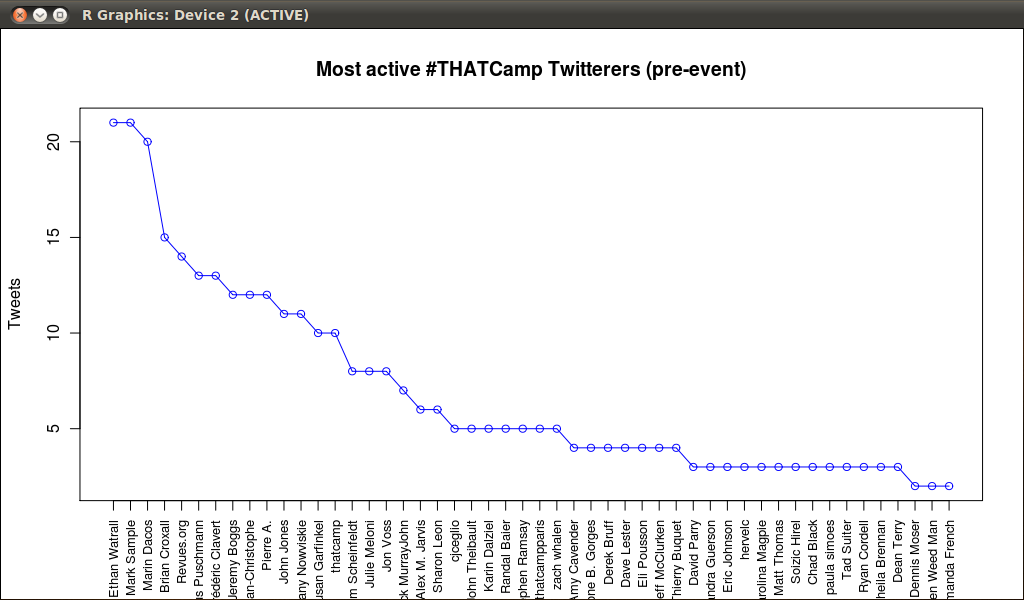
There’s been a number of posts on visualizations already, so I will add my own perspective to those who came before. Two of my chief interests in this conference are how you can make visualizations more interactive and how we can streamline or design for multiple languages and publishing platforms at once.
A lot of digital humanities projects try to create tools and standards in processing of their respective data, whether it be a historically focused multimedia site or a literary criticism databank. Many of these projects rely on multiple stages of processing — crowdsourcing or digitization, geospatial and relational databases, logic and data mining, interface and presentation for the application of still more algorithms and application of new sources. This allows for both competition and reinvention of the wheel in many cases. When is the wheel not good enough, and when will a framework like ruby on rails become available with sufficient flexibility to allow digital humanists control over their projects without necessarily working from scratch or related but generic open source platforms?
Visualization and standards remain a topic of interest to me: Hugh Cayless proposes that we take a serious look at how new design patterns could help digital humanists develop future projects with the best practices . Visualization proposals by Daniel Chamberlain and Cornelius Puschmann suggest we should look at the new frontiers of visualization as well as re-evaluating existing applications.
When I originally submitted, I had an idea of introducing one platform’s new features and how they could impact textual scholarship and visualization. Here’s a quote from my original proposal:
Research in the digital humanities has increasingly become dependent on software visualization techniques and interface design in both the presentation and analysis of its subjects.
…
Adobe has released another version of AIR and the Text Layout Framework, both important contributions to the digital humanities. The second allows for a more sophisticated and clean presentation of textual data and the first allows a closer native interface with other programs and frameworks which can accomplish tasks that Flash cannot.
I’d like to start a conversation about the menagerie of visualization and processing technologies; how the ease of interface design in AIR could be tied to the powerful, expressive programming of LISP or PROLOG. The Digital Humanities is in part dependent on the strength, flexibility and appropriateness of the programming tools it uses. If the tools involve the nebulous potency of cloud computing or the proven algorithms of artificial intelligence, the idea of combining multiple platforms together and making them play well remains a direction the field is headed. AIR’s native support and its graphics-oriented language, ActionScript, provide one means of realizing this.
This sounds like quite an argument for Adobe Flash, but with platforms such as the iPad recently blackballing Adobe’s technology, we are forced to resort to multi-pronged approaches, possibly developing for multiple platforms simultaneously. The iPad has already been the source of a number of successful academic projects like the International Children’s Library released as apps and as web sites.
I’m less interested in the debate of facts such as the current legal or policy stance Adobe or Apple has taken to their respective technologies, and more interested in pragmatic solutions taking those restrictions into account.
As I understand it, the digital humanities has the potential to become a meta-discipline for the humanities and scholarship in general, where its domain incorporates, along with new media projects and data curation activities, the advancement of scholarship in many related disciplines. An excellent example of this is the sort of progressive projects like Hacking Academia which seek alternatives to the ports of existing publishing systems.
Though not a part of my original scope, I am also very interested in new approaches to game development and ways of engaging readers/players/students through games.